Hi guys. My name is [Aseem Kishore](http://aseemk.com/). I'm a developer at a startup here in NYC called [FiftyThree](http://www.fiftythree.com/). We make an iPad app called [Paper](http://www.fiftythree.com/paper).
I'm here to share an intro to graph databases generally and [Neo4j](http://www.neo4j.org/) specifically, walk through Neo4j usage from Node.js, and share my experiences and lessons learned building a startup on top of both!
(Image from [drupal.org](http://drupal.org/project/all_the_things))
[](http://www.fiftythree.com/)
If you aren't familiar with [FiftyThree](http://www.fiftythree.com/) or [Paper](http://www.fiftythree.com/paper), definitely check it out.
It's worth noting that I can't take any of the credit for Paper's quality or success. That's all the amazing work of the other folks at FiftyThree. I'm leading the development of our next product, which we haven't announced yet.
[](http://www.thethingdom.com/)
Before I joined FiftyThree, I built a startup called [The Thingdom](http://www.thethingdom.com/), which was a social network around products. I built this with my friend and co-founder, [Daniel Gasienica](http://gasi.ch/). This is him (and his photography gear) pictured here.
[](http://zoom.it/)
When Daniel and I started building The Thingdom, neither of us had had any significant experience working with relational databases.
We had some solid experience using a key-value store: we had built this "bit.ly for high-res images" type of site and service called [Zoom.it](http://zoom.it/). But early on, we realized that a highly partitioned key-value store didn't quite make sense for a social network like we were building with The Thingdom. After all, how do you partition arbitrarily-connected data? We didn't know.

So we did what (hopefully?) any other ignorant and naive pair of developers would do: we googled it. Surely in the era of Facebook's Graph API, this must be a solved problem.
We expected to just find techniques and best practices explaining how to use either a regular relational db or a key-value store to implement a graph, but we were surprised to hear that there were actually dedicated "graph databases" for this kind of data.
[](http://www.neo4j.org/)
There appeared to be a bunch of options, and we settled on what has turned out to be the most mainstream one, [Neo4j](http://www.neo4j.org/). We tried it, and we liked it, so we decided to stick with it. And it turned out to be a great choice.
In fact, I've often said that this decision was probably the *best* technology choice we made. Not because of scale or anything like that, but simply because it let us build our *app* and focus on the user experience rather than the format of the data being stored.
It sounds cliche, but we were truly able to translate whiteboard sketches directly to our data model, with no (or minimal) futzing in between. And that meant that we were able to crank out features and iterate rapidly on them. The simple programming model and schemaless structure were key factors here.
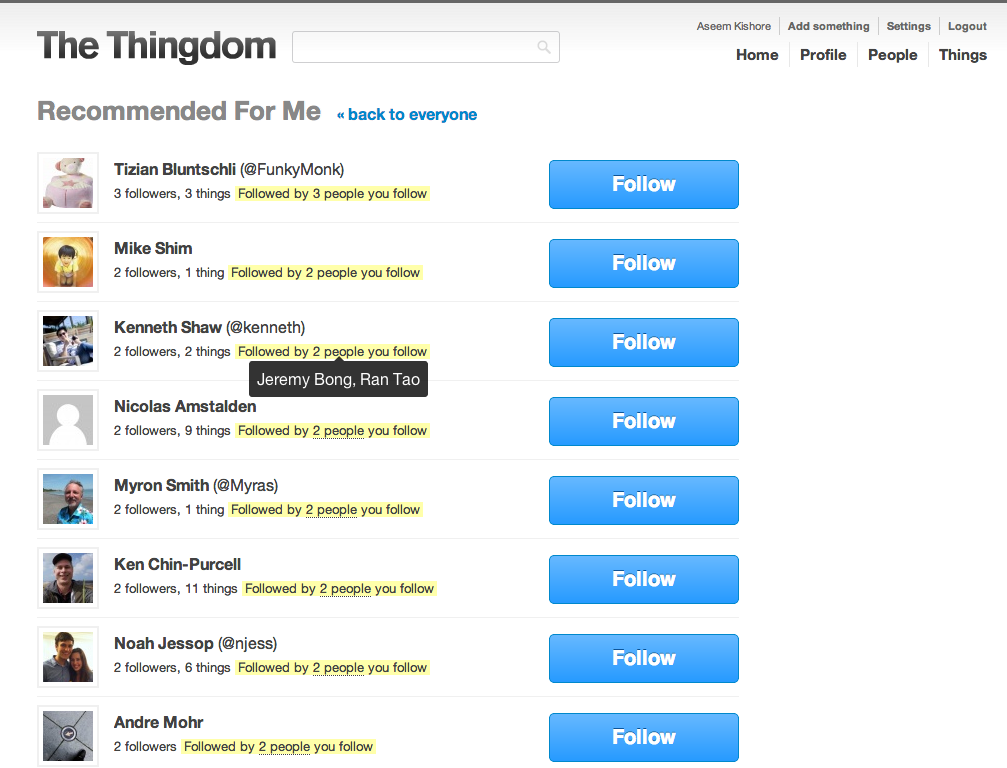
For example, we were able to not only show recommendations for people you might like to follow, but also show *why* we were recommending those people to you (e.g. their followers that were also your following) -- all in real-time.
We were also able to easily implement more advanced features (even if we never got around to implementing the UI/UX for those features -- that was always the hard part and the bottleneck for us), like helping you discovering things you have that another person wants (or vice versa).
With Neo4j, we were able to not only express these kinds of questions with straightforward queries, we were also able to *answer* those questions efficiently, often in real-time again.
So that was pretty exciting, and potentially even a source of competitive advantage if we found success with such features.

But more than anything, this was my favorite technology choice because it simply made us happy and productive. We never dreaded schema upgrades or struggled over table design. Using a graph database was just *fun* -- and you can't underestimate the importance of that when doing a startup.
(Pic from [pdnpulse.com](http://pdnpulse.com/2012/04/sign-of-the-times-has-13k-of-camera-gear-uses-phone-instead-friday-photo-fun.html))
[](http://gasi.ch/)
Daniel Gasienica
I should pause at this point and give credit where credit's very much due: it was my co-founder, [Daniel Gasienica](http://www.gasi.ch/), who made us go in this direction. I was actually skeptical at first! Thanks Daniel. =)
# So…
##
# Just what is a
# graph database ?
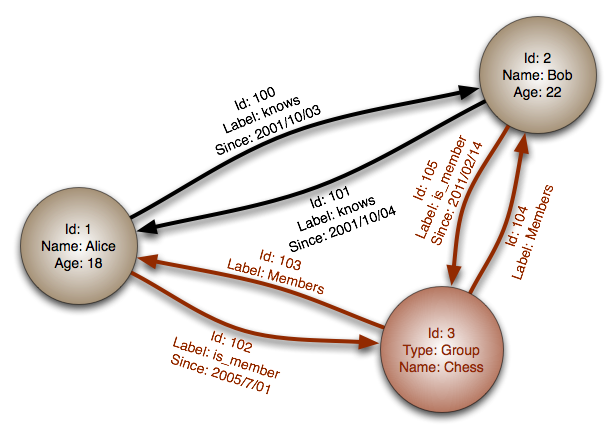
"Graph database" obviously implies that the database stores data in a graph format or that it's optimized for graph operations.
Generally, graph databases store "property graphs" -- which means nodes and relationships can have properties attached to them. You can think of nodes and
relationships as "records" then, kind of like rows in a table.
Graph datbases also generally label relationships -- it's the one "type" or "schema" that graph databases need to know about.
(Pic from [Wikipedia](http://en.wikipedia.org/wiki/Graph_databases))
There are generally two main ways to represent a graph, and indeed, a graph
database would probably store the graph (at a high level) in one of these two ways.
An "adjacency list" representation keeps track of each node's neighbors (which are nodes here, but would probably be relationships to nodes in practice), whereas an "adjacency matrix" representation tracks whether any given pair of nodes are neighbors (or more precisely again, have one or more relationships connecting them).
Adjacency lists are optimized for sparse graphs, while adjacency matrices are optimized for dense graphs. Most graph databases would probably then store an adjacency list, since the density of the graph won't be known in advance.
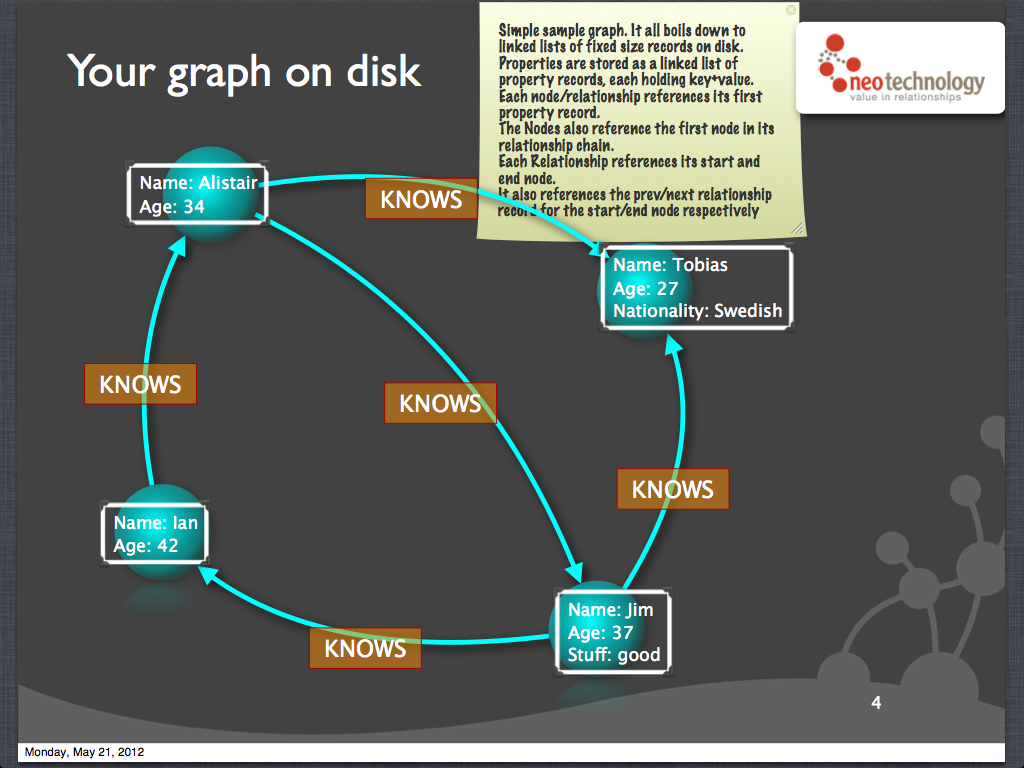
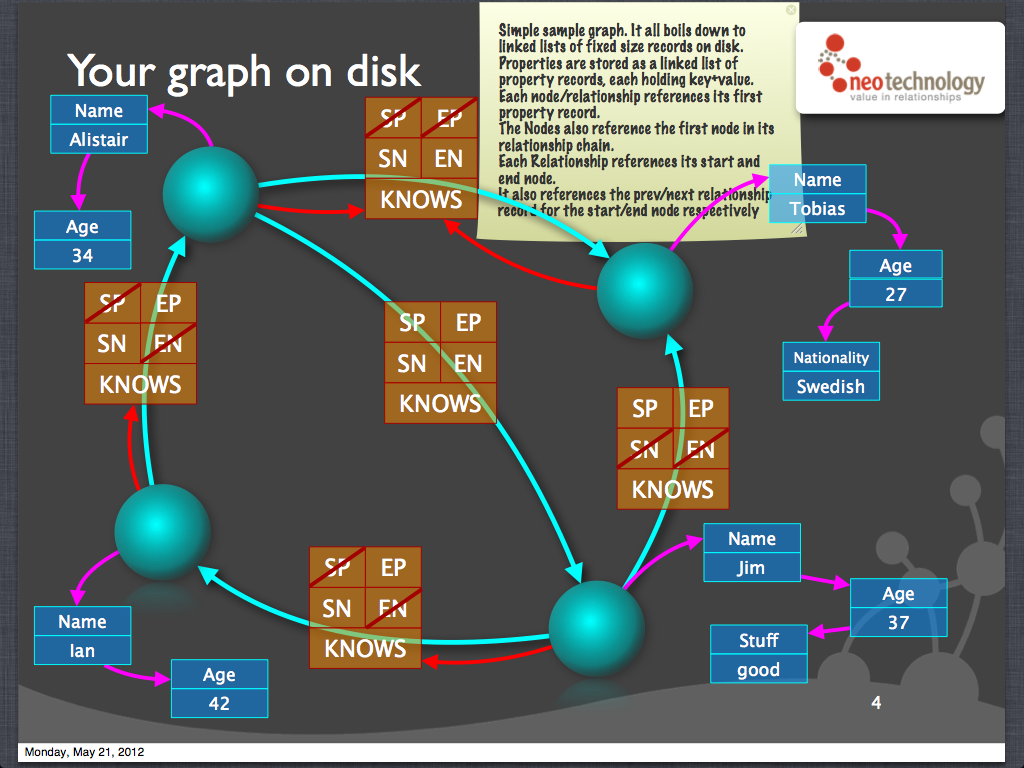
And indeed, that's how Neo4j stores its data. It happens to use doubly-linked lists for everything, but the idea is the same: for each node, there's a list of its incoming and outgoing relationships.
Neo4j also uses fixed-size records for both nodes and relationships, with each record offset by its ID, so that if you know the ID of a node or relationship, a direct lookup is O(1). To achieve the fixed-size records, the records contain only "head" pointers to their linked lists.
This is really useful to know, because it shows you a few properties of Neo4j (and maybe graph databases in general):
- It's great at localized searches. E.g. to get the people you follow, it just needs to follow your node's linked list of relationships -- and the performance of this won't change if there are 100 people globally or 1M.
- It's not great at aggregation. E.g. the nodes or relationships aren't stored in any sorted order, so deriving the 20 most popular users requires a full scan.
- It suffers from the "supernode problem". At least currently, a node's neighboring relationships are stored as a flat list, so if you have a million followers, fetching even one person you follow is slow. This could be solved by storing neighbors as a hash table or a B-tree, but there are other trade-offs then, too. We'll come back to this.
(Slides from [Tobias Lindaaker](https://github.com/thobe), Neo4j engineer; retrieved from [slideshare.net](http://www.slideshare.net/thobe/an-overview-of-neo4j-internals))
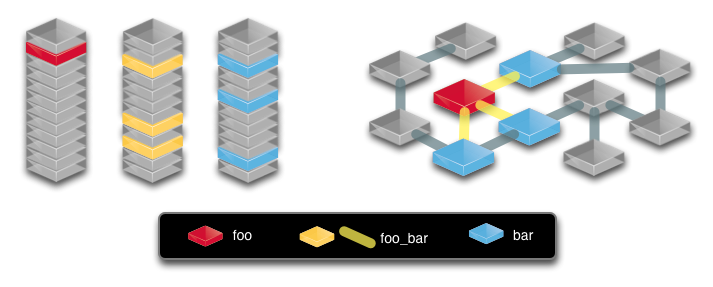
Graph data can also be stored in a relational database, of course. Here's how a simple graph might translate between the two. And this is what shows the localized aspect of graph databases so clearly: the relationships between `foo` and `bar` require a lookup in a large single table in the relational representation, but they're stored local to `foo` and `bar` in the graph representation.
(Slide from [Andreas Kollegger](https://twitter.com/akollegger) I believe, another Neo4j engineer; retrieved from [systay.github.com](http://systay.github.com/blog/2011/11/06/cypher---a-view-from-a-recovering-sql-dba/))

I can't speak to this, but I've also heard that you should consider using a graph database if you find yourself doing multiple or complex JOINs like this. =)
(Pic from [yobriefca.se](http://yobriefca.se/blog/2012/11/02/neo4j-talk-in-november/))
By definition, a graph database is any storage system that provides index-free adjacency .
This means that every element contains a direct pointer to its adjacent element and no index lookups are necessary.
And here's where we get to the "formal" definition of a graph database: it's a database that provides *"index-free adjacency"*. Every element contains a direct pointer to its neighbors, not requiring a global index lookup in between. You could also think of these as "local" indices.
(Quotes from [Wikipedia](http://en.wikipedia.org/wiki/Graph_database))
# Querying
Start somewhereTraverse elsewhere
This is how you query a graph database in general...
# Querying in Neo4j
Start somewhere
Root node
ID directly (file offset)
Lucene index
Traverse elsewhere
Traversal APIs
Cypher patterns
Built-in graph algos (Djikstra, A*, etc.)
...And this is how that translates to options in Neo4j.
# Neo4j usage
Embedded mode (Java API)Server mode (REST API)Cypher query language (both)
This is how you can use Neo4j.
- Embedded more is essentially a JAR you include in your Java app, and that gives you a Java API for working with a local Neo4j database. This is the richest, most performant and flexible way of using Neo4j.
- Running it as a server originally meant writing your own Java server, but today Neo4j comes bundled with a (Jetty-powered) server. This exposes a documented REST (JSON) API that maps roughly to the Java API, but is a bit more limited and less flexible.
- Finally, you can use Neo4j's query language, Cypher, through both the Java API and the REST API. There's also the choice of Gremlin, another query language, but whereas Cypher is declarative, Gremlin is procedural.
# Our usage
## **Node.js**
+
## **REST API**
+
## **Cypher**
This is how we used Neo4j.
[](https://github.com/thingdom/node-neo4j)
And when we started, there wasn't a formal Neo4j client library for Node.js, so we built and open-sourced our own. Check it out if you're interested: [thingdom/node-neo4j](https://github.com/thingdom/node-neo4j). Feedback, pull requests, etc. always welcome.
It was at this point in the presentation that I gave a code walkthrough and demo of a node-neo4j sample app, [aseemk/node-neo4j-template](https://github.com/aseemk/node-neo4j-template), as well as demoed and explained some sample queries on [console.neo4j.org](http://console.neo4j.org/).
# Neo4j editions
Community edition
Single instance
Offline backup
Advanced edition
Enterprise edition
Multi-instance cluster!
Online backup!
Neo4j is open-source, but comes in three different editions.
- The community edition is completely free to use, but doesn't have advanced features like clustering or online backup.
- The enterprise edition, on the other hand, is industrial-strength, but requires you to pay if you're not an open-source app.
- The advanced edition is fairly pointless in my view. It doesn't offer much beyond the community edition, but also requires you to pay.
# Neo4j scaling
Master-slave replicationCache-based shardingFeature-based polyglot'ing
64B limit on nodes, rels, props
But can be easily upped; just flipping some bits
100 props/node (high) ⇒ 640M nodes
And this is how Neo4j scales.
- Since graphs aren't trivially partitionable, Neo4j isn't trivially shardable, so it scales through master-slave replication. Writes all go to a master, while reads can go to any slave; this is typically fine for most applications that have orders of magnitude more reads than writes.
- For advanced scaling, you can "shard" Neo4j's memory cache across slaves by sending queries for different parts of the graph to the same instances each time. This'll increase the likelihood of cache hits for each instance, improving your read throughput.
- Of course, if you *actually* hit walls scaling, at that point, you could/should consider sharding by features, not parts of the graph. So e.g. the parts of your data that aren't connected at all could go into a key-value store, etc.
- Finally, it's good to be aware of the limits on nodes, relationships, and properties, since the graph has to be stored in full on each instance. But these limits are soft limits -- they're determined just by the size of the fixed records on disk, so they can be trivially upped if you need. They're already quite high as is for most apps.
# Okay...
##
# Let's talk about
# what we learned
We'll do this by going through a few examples of things we ran into when designing various features.

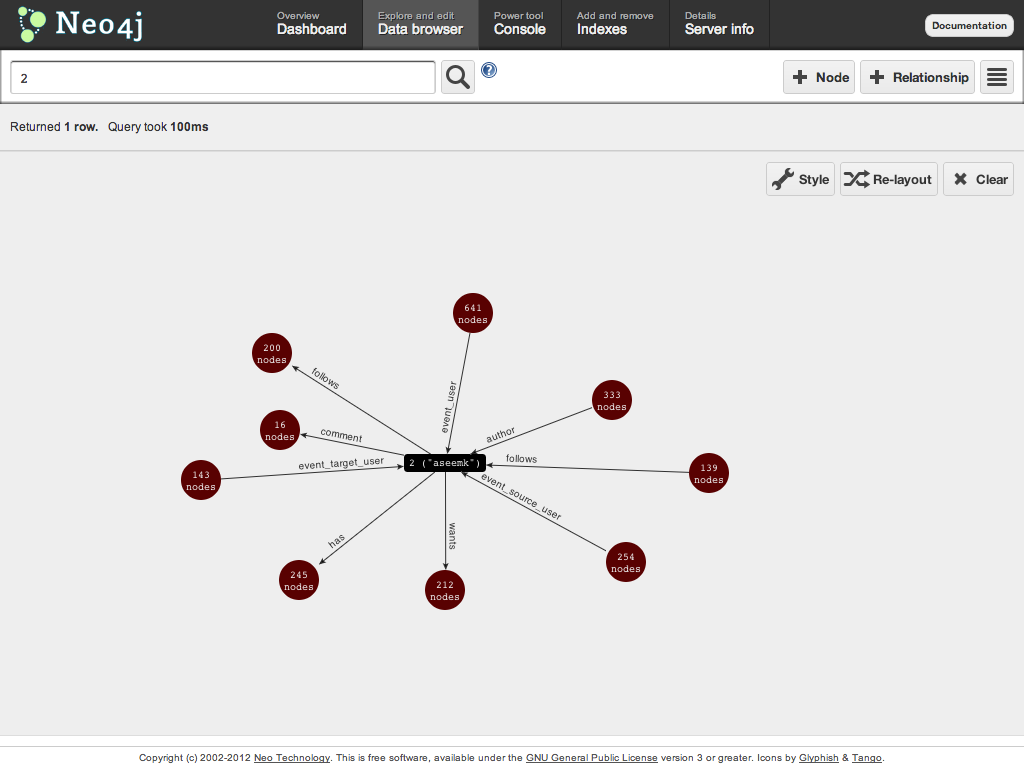
Here's the basic social graph for The Thingdom. It's pretty straightforward, but note how the relationship names are unique and expressive -- they tell you how two nodes relate, and they let you easily find one type of node from another.
# What we learned
Unique, expressive relationship types
Sounds simple, but that's an important lesson that was reinforced to us over and over. It's tempting to stay "pure" by using "simple" names like `likes` and `follows` and `author` everywhere, but don't overload them. It's always easy to query for both types of relationships when the names are different (just an `OR` in Cypher), but it's not possible to (efficiently) query for just one type when the names are the same.
E.g. at some point, we were considering letting people "follow" categories/brands too, but we resisted the temptation to reuse the `follows` relationship name. If we had, we wouldn't have been able to efficiently traverse just the *users* someone followed, or vice versa.
And again, the way Neo4j stores data on disk, the relationship type is the only way it knows during a traversal whether to visit a node or not. Unique and expressive relationship types can save you a lot in performance.
Like any social network, we also obviously wanted to show users' stats whenever we showed a list of users. But it obviously wouldn't be performant to fetch all these followers and things for each user everytime. So we cached those numbers as properties on user nodes, e.g. `numFollowers` and `numThings`.
# What we learned
Unique, expressive relationship types
Cache stats where possible
Again, simple enough, but it makes a dramatic difference, so don't forget that.
This applies at each level, though, both per-node (e.g. each user's `numFollowers`) and globally (e.g. the most popular categories; these could be cached as relationships from the root node, or those nodes could be indexed).
Avoid expensive traversals and aggregations wherever you can.
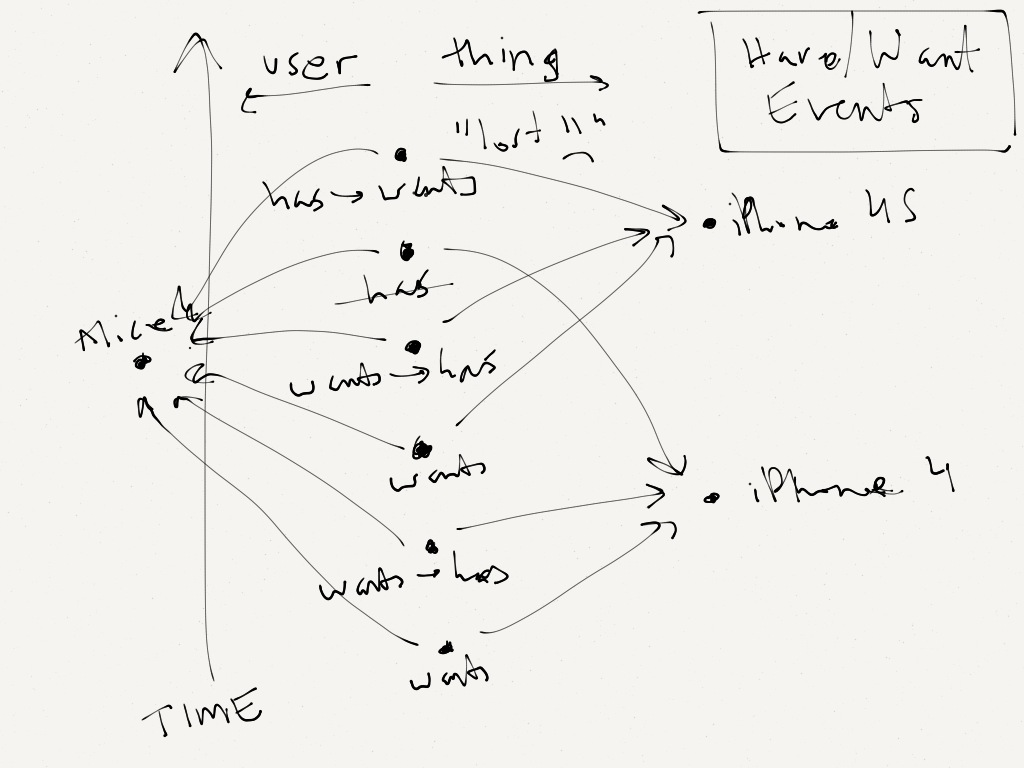
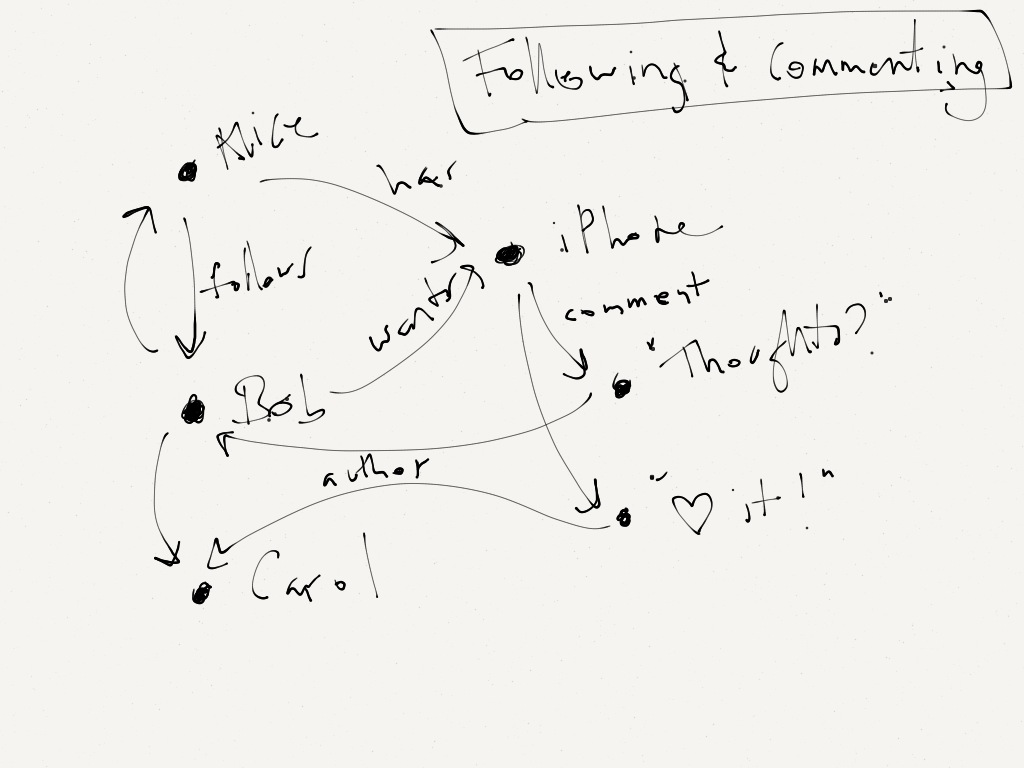
I showed earlier that our basic graph was that users were connected to things through `has` and `wants` relationships. That worked fine for the present -- this moment in time -- but how does that work over time, when those relationships can change?
E.g. a user wants the new iPhone before it's out, then when it's out, he/she gets one, then months later, he/she loses it by accident, etc.
We obviously want traversals to be efficient when we're querying e.g. who wants this iPhone, or what things does a user have. But we may also want to "remember" that history, as we did.
To achieve both those things, we settled on a philosophy that worked well for us: we decided that relationships reflect the "state of the world" at this moment in time, and *event nodes* could be used to capture history.
So in this case, we came up with "have/want event" nodes, which, like `has` and `want` relationships, connected users with things, but also stored (as properties on the node) the type of change (e.g. `has` → `wants`).
This was better than e.g. keeping relationships around forever and storing `deleted` properties on relationships we should ignore, because traversal performance would have suffered.
# What we learned
Unique, expressive relationship types
Cache stats where possibleCapture history through event nodes
So if that works for your domain too, consider keeping relationships lean in number and simple -- just the state of the world -- and capture history through "event" nodes, which can be ignored for "now" queries.
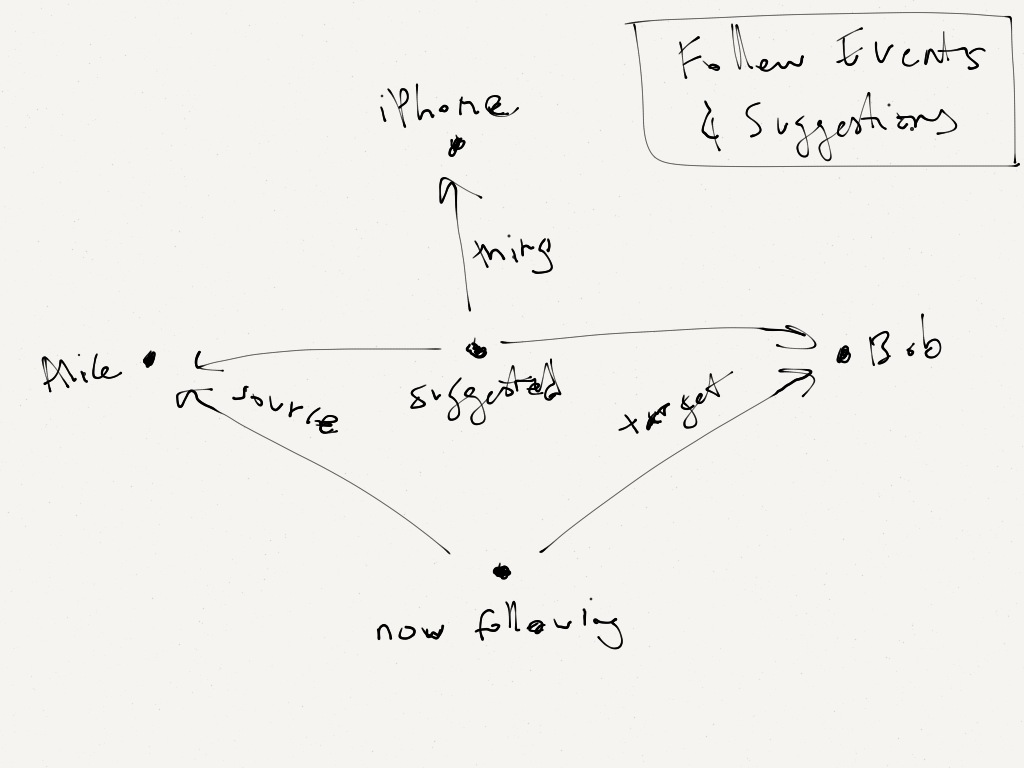
But we also learned another lesson from that experience: we noticed that these event nodes let us (and our users) do things we couldn't do with the simple `has` and `wants` relationships. Other users could "like" an event node, or comment on it, or be @mentioned by a decsription on it.
That taught us another important lesson: nodes let something truly be "first-class" in a way that relationships couldn't. And that's simply because relationships can't point to other relationships.
(These are known as "hyperedges" in graph terminology. Some graph databases may support them, but Neo4j doesn't. I used to wish that it did, but I'm realizing that ultimately, it's not a big deal, since you can easily achieve hyperedges with node and relationship "primitives" like this.)
So at some point, when we implemented a feature to let users suggest things to other users ("Alice thinks you might have or want an iPhone"), we had no choice but to implement those suggestions as nodes (since they connected three nodes, not just two), but we were happy to do so, since that again let us do "first-class" things with them, like letting other users comment on them. Win-win.
# What we learned
Unique, expressive relationship types
Cache stats where possibleCapture history through event nodes
First-class objects ⇒ nodes , not rels
So remember that relationships are limited to connecting just two nodes. If you're modeling something that you may want to support multiple connections to, make it a first-class node.
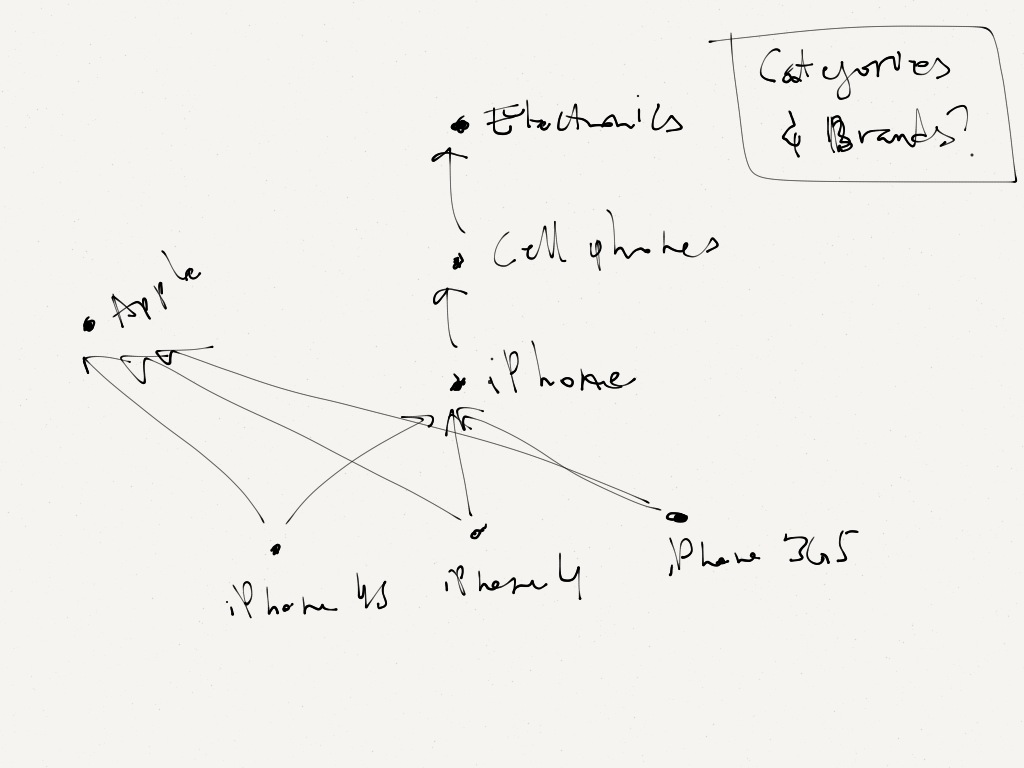
We made a similar mistake when it came to curation/categorization. What's pictured here is what we *should* have done: have nodes for categories (and in this case, e.g. brands too), and have thing nodes connected to those category nodes. That would have let us even have a hierarchy of categories/subcategories, like pictured here.
Instead, we took the shortcut of adding a category *property* to our thing nodes. After all, we figured that would still let us query and derive things' categories, and we could even (auto-)index that property.
However, we again ran into limitations as we realized that properties are equally not "first-class" citizens of the graph. But besides the abilities of e.g. users being able to follow/like categories, or comment on them, even the simplest things, like renaming a category, were now hard(er) to do, because the categories were duplicated/fragmented all over the place.
# What we learned
Unique, expressive relationship types
Cache stats where possibleFirst-class objects ⇒ nodes , not rels
Capture history through event nodes
Connected data ⇒ nodes , not props
So again, if something in your data model is important enough to warrant working with, consider making it a "first-class" node. But in this case, if it's also *connected* data, like our categories were, it should definitely be a node, not a property.
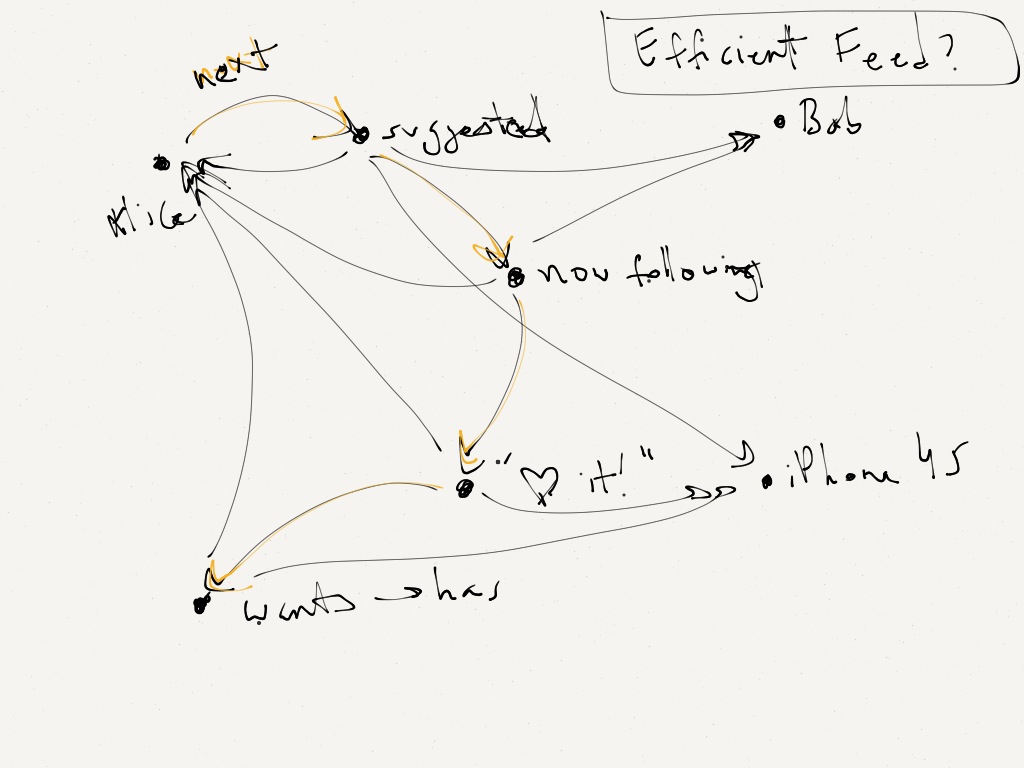
Finally, maybe the most important lesson we learned was around our activity feed implementation. This was probably the most important lesson because it's not necessarily obvious if you're new to graphs / graph databases, but it's also one of the most fundamental.
As we saw with Neo4j's file format, the performance of traversing a node's relationships scales linearly with the number of those relationships. Having unique, expressive types on those relationships lets you cut down on the number of *nodes* that are visited, but each of the *relationships* must still be visited, because the relationships are (currently, at least) all stored as one, flat list.
So when a node starts to have many, many relationships, efficient traversal becomes a problem for that node. This is called the **supernode problem**. And this is indeed what happens when you implement "event" nodes for users like we did: the number of relationships for a user keeps growing and growing (because the number of event nodes they're connected to keeps growing and growing).
So when we implemented our activity feed, we went the simple/naive way of using a Cypher aggregation on users' event nodes: essentially, an `ORDER BY` followed a `LIMIT`. This meant that Neo4j had to traverse every relationship -- *and* visit every event node -- in order to determine the top (most recent) events. This kind of aggregation is obviously not making good use of a graph database, and we saw how this didn't scale as our data grew.
This picture shows what we *should* have done: make use of the most basic graph data structure -- a linked list. We should have maintained a linked list for each user's events, and appended to (the front of) it on each new event for that user. This would let us follow just the first 10 (or 20, or whatever) relationships -- a constant number instead of growing with the number of events.
The supernode problem still exists for the first relationship, since the user node has many relationships. The Neo4j team has plans to remove this problem by reworking the file format (e.g. storing a node's relationships as a hash table or B-tree instead of a flat list), but until then, you can simply use a global index: for each user, index the "head" relationship for that user to his/her most recent event node.
Hat-tip to [René Pickhardt](http://www.rene-pickhardt.de/) for opening my eyes to this approach through his work on [Graphity](http://www.rene-pickhardt.de/graphity-an-efficient-graph-model-for-retrieving-the-top-k-news-feeds-for-users-in-social-networks/), a project which applies the same idea to *aggregate* feeds as well.
# What we learned
Unique, expressive relationship types
Cache stats where possibleFirst-class objects ⇒ nodes , not rels
Capture history through event nodes
Connected data ⇒ nodes , not props
Maintain linked lists for O(1) queries
And that's the last major lesson we learned for making the most of a graph database. This approach of storing linked lists is also sometimes referred to as creating secondary "in-graph" indexes.
# Neo4j Roadmap
Overhaul of indexing API
Relationship type grouping
Socket and/or binary protocol
Automatic sharding?
Going forward, we're pretty excited for a few improvements and developments to Neo4j specifically.
- They plan to integrate indexing much more tightly into the data model, like letting you specify primary and secondary keys to index on for different "types" of nodes. This'll also let you write to indexes via Cypher, which will be nice.
- They're aware of the supernode problem and have plans to fix it, as I mentioned. Storing relationships as a map or B-tree will go a long way, but I understand there are trade-offs to any representation.
- Right now, the only APIs to Neo4j are Java and REST. HTTP has lots of overhead, so they're actively exploring a binary protocol. This apparently already shows huge performance improvements, and could be a transparent upgrade to Cypher usage.
- Graphs aren't trivially partitionable, as I mentioned, but if anyone has the knowledge to figure out how to do it heuristically -- and connect the pieces together -- it should be a graph database. I believe they're already working on this problem, which is pretty cool.
Overall, it's been great to grow with Neo4j and be a part of the community, and we're still as excited as ever for its future.
**Update:** the Neo4j team in fact just published a blog post on this stuff! [What's coming next in Neo4j](http://blog.neo4j.org/2013/01/2013-whats-coming-next-in-neo4j.html)
[](http://www.fiftythree.com/)
And that's that!
So check out [FiftyThree](http://www.fiftythree.com/) and [Paper](http://www.fiftythree.com/paper) again if you haven't already. We're very much looking forward to shipping what we're building with this tech.
# Thanks!
### Twitter: [@aseemk](https://twitter.com/aseemk)
### GitHub: [@aseemk](https://github.com/aseemk)
### Email: [aseem.kishore@gmail.com](mailto:aseem.kishore@gmail.com)
Questions?
And thanks to [Reveal.js](https://github.com/hakimel/reveal.js) by [Hakim El Hattab](http://hakim.se/about) for the excellent platform on which this presentation was created.
If you want to see how I created this slides+notes [combo viewer](https://github.com/hakimel/reveal.js/issues/304), don't hesitate to [view source](http://github.com/aseemk/aseemk.com). ;)
I hope this presentation helped, and I look forward to seeing all the great things you build too!
Cheers,
 ### With Node.js and Neo4j
#### Aseem Kishore / Apr 2013
### With Node.js and Neo4j
#### Aseem Kishore / Apr 2013